(1)提出跨模态信息获取和表征的统一模型
跨模态信息(听、看、触、嗅、味等)通过无线通信系统传输至接收端重现,将为用户带来更极致的互动体验和更丰富的场景体验。然而,不同模态信息的感知机理不同,缺乏跨模态信息获取和表征的统一模型;音频、视频、触觉、嗅觉等信号之间性能指标差异显著,传输保障难度加剧;音频、视频、触觉、嗅觉等信号的表现形式各异,以沉浸式体验为目的的综合展现方法还有待突破。工程中心周亮教授团队提出的跨模态原型系统通过研究多模态数据的普适化感知及其表征模型、多模态数据的混合编码设计、多模态异构码流按需调度技术与传输协议设计以及面向沉浸式体验的跨模态信号恢复与重建四个模块共同实现音频、视频和触觉跨模态通信,在远程医疗等应用中提高用户沉浸式体验。
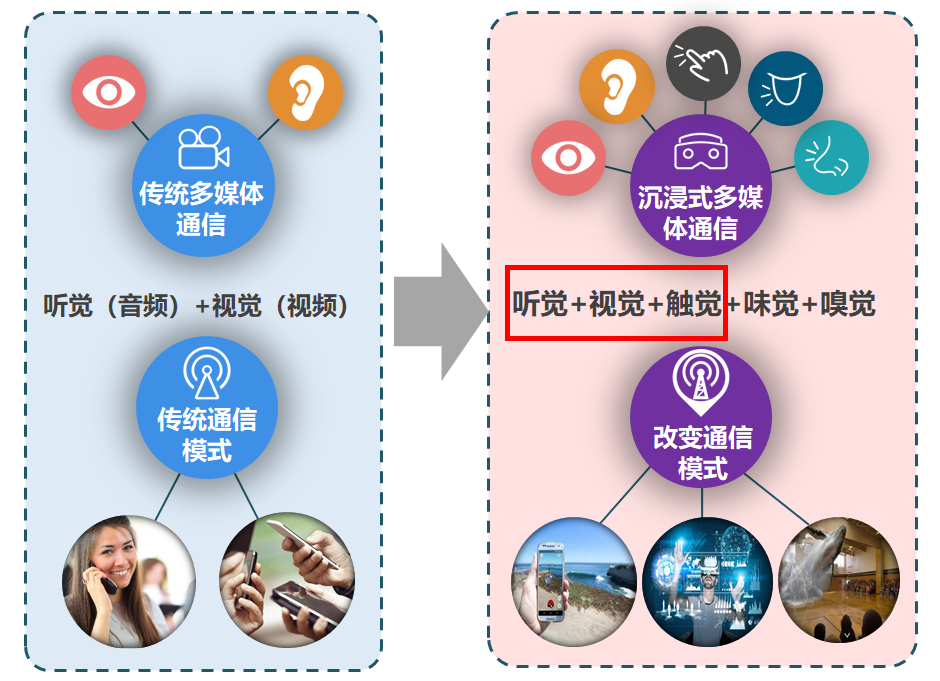
图1以沉浸式体验为目的的跨模态原型系统
(2)提出音-视-触跨模态通信架构
周亮教授团队专注于探索传统视听服务和新兴触觉服务的相互加持潜力,以期为多媒体用户带来更沉浸式的互动感受和场景体验。针对音频视频和触觉信号在物理特征、传输需求、呈现形式等维度上存在巨大本质差异的问题,提出音-视-触跨模态通信架构,包含触觉信号编码、多模态异构码流传输、跨模态信息重建三个方面。
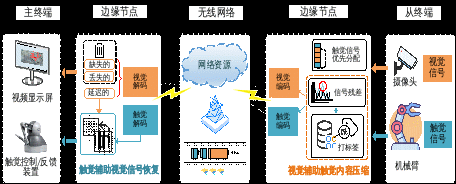
图2 跨模态传输策略框架
项目团队基于用户触觉感知机理实现了高效鲁棒的触觉信号编码方案,为实现多模态信号的压缩提供了理论依据;同时通过利用码流传输的时空分布不均,提出一种边缘智能赋能下的多模态异构码流传输策略;且通过模态间语义层面的融合及共享,探索了智能、完备的跨模态信息重建机制设计空间。相关理论方法和实践演示属国际标杆,重要成果发表在IEEE JSAC、IEEE NETWORK、IEEE TMM等通信和多媒体领域高水平期刊上,引起了国内外知名专家的广泛关注,为尚在起步阶段的跨模态通信与触觉互联网的研究提供了有力借鉴和启发。
(3)跨模态生成
深度融合文本到图像生成对抗网络根据文本生成图像任务要求计算机能够由文本生成对应的图片,由于其为创作带来的便利性,使其在互联网时代有着重要的研究价值和意义。该任务会给定一段文本,要求模型能够充分理解文本中蕴含的语义信息,并将文本中的语义信息映射为图像中对应的视觉信息,从而得到真实且符合文本描述的图像。利用生成对抗网络进行对抗学习是解决该任务的主要方法之一,在对抗学习中,判别器需要区分生成图片和真实图片,而生成器则需要生成足够逼真的图片,使得判别器无法区分生成的和真实的图片,通过生成器和判别器之间的互相博弈,从而提高生成图片的质量。
提出了一个简单且有效的一阶段文本到图像生成框架,它可以直接由文本生成高分辨率的图片,避免了多阶段框架带来的特征纠缠问题。在生成器中,我们提出了一个深度文本-图像融合模块,通过堆叠基于文本的图像仿射变化,加深了文本与图像的特征融合,从而使得文本信息能够更好的表达在图片中。在判别器中,我们提出了一个目标感知判别器,它由两部分组成,包括一个匹配感知梯度惩罚策略和一个单路判别器。这两个模块构造了一个利于收敛到目标图片的判别器损失曲面,使得模型可以更快且稳定地收敛,从而使得模型得到更好的优化。
通过定性和定量的实验表明,所提出的方法在简化当前生成网络的同时,优化了生成图像的质量,并且提高生成图像与文本的匹配度。
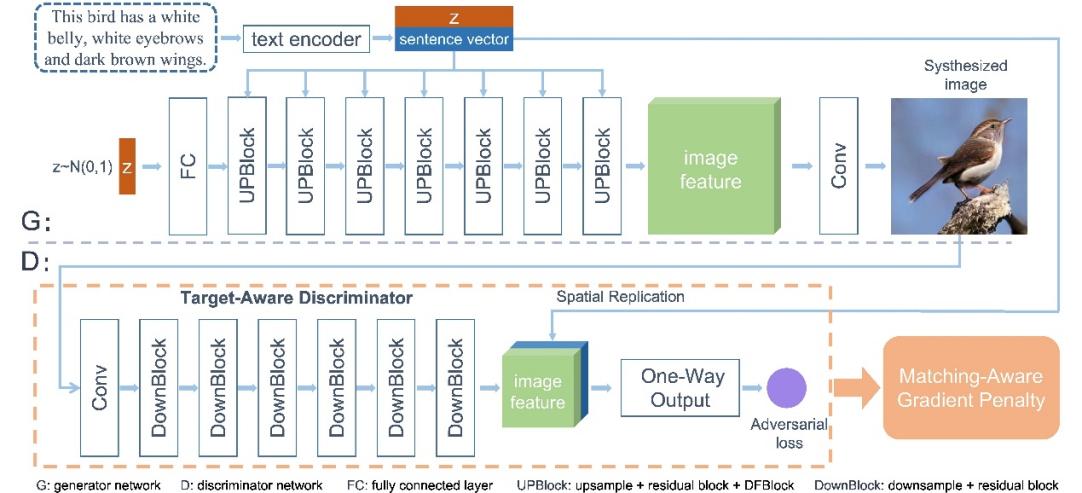
图3深度融合文本到图像生成对抗网络
跨模态语义通信理论与关键技术研究,国家自然科学基金重点项目,项目号62231017,主持人周亮,在研,2023.01-2026.12
面向沉浸式体验的跨模态通信关键技术研究,国家自然科学基金面上项目,项目号62071254,主持人魏昕,在研,2021.1-2024.12