近十多年来,基于深度学习的智能信号与信息处理技术高速发展,人类提前进入了智能时代。在智能信息处理技术中,信息分类是最基本也是最常用的应用之一。尽管在众多标准化数据集上,深度学习的分类模型取得了媲美人工分类的准确率,但许多实际场景与模型训练时的场景有着明显差异,尤其许多实际场景的数据无法预先获得标签信息,使得经典深度学习模型的泛化能力面临严峻的挑战。域自适应理论利用应用领域的数据来实现自适应的模型调整,有效克服了深度学习模型依赖于训练数据分布的缺陷,同时满足了应用领域的复杂性和多变性需求,因而成为当前深度学习的研究热点之一。工程研究中心杨震教授研究团队从无标签目标域的自适应问题出发,面向深度学习的两个热点应用领域—图像分类和新药筛选,分析深度学习模型在泛化性方面的不足。在此基础上,通过研究度量学习、伪边缘以及筛选回归等新的深度学习理论、方法和技术手段,提升模型在复杂和多变环境下的泛化性能。
(1)提出度量学习协助的域自适应算法和通用域自适应图像分类方法
针对图像分类中易误分类的问题,分析了传统域自适应(Domain Adaptation: DA)方法在源域和目标域特征分布对齐时,源域与目标域图像分类误差之间的关系。本文结合度量学习准则,通过在源域引入具有动态边缘的三元组损失函数,进一步控制域对齐后目标域图像分类的误差,并据此提出新的DA算法:度量学习协助的域自适应算法MLA-DA(Metric-Learning-Assisted Domain Adaptation: MLA-DA)。该算法在源域图像的分类学习中有针对性地增加分类边距,使得域对齐后分类边界相对目标域图像更加宽裕。理论和实验结果表明与经典域对齐算法相比,MLA-DA算法在目标域图像分类上具有更好的鲁棒性和泛化性能。
针对图像分类中通用域自适应(Universal Domain Adaptation: UDA)问题,分析了源域图像分类器在目标域图像分类的概率分布,并探索该分布与公共类别集识别的关系。提出了一种利用伪边缘(Pseudo-Margin: PM)的通用域自适应方法,实现公共类别集的精准识别。此外,面向实际应用中目标域图像的类别集完全未知的场景,提出了一种表征源域图像类别在目标域图像中出现概率的模型,并构造了伪边缘向量。然后通过基于伪边缘向量的类级加权对抗训练,尽可能地将公共类别集图像样本的特征分布对齐。实验结果表明,基于概率模型和伪边缘的图像通用域自适应理论,能够准确地识别公共类别集的图像,并取得较好的未知目标域图像分类性能。
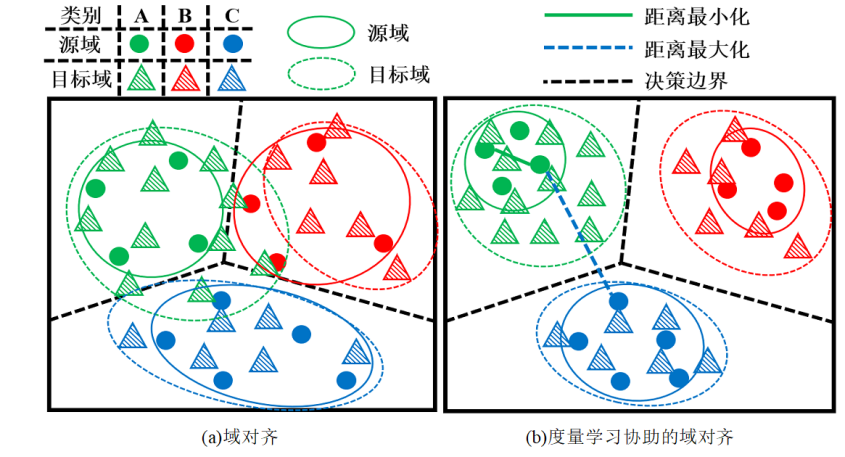
为解决多源图像分类中多样性和差异性的矛盾,提出了联合域对齐的技术,同时对齐多个不同的源域图像之间、源域图像与目标域图像之间的公共类别集样本分布,并开创性地提出通用多源域自适应(Universal Multi-Sources Domain Adaptation: UMDA)理论。在此基础上,设计了一种通用多源自适应网络(Universal Multi-Sources Adaptation Network: UMAN),进一步提高通用图像分类的性能。UMAN以基于伪边缘的通用图像分类的研究为基础,提出联合的多源域图像分类器和对抗损失,有效消除各域样本分布之间的差异,并显著降低系统的复杂度。理论和实验结果表明,采用联合的多源域图像分类器和联合的域对齐损失函数,能够提升深度学习模型的泛化性和鲁棒性,特别是在源域数量多、差异大的复杂场景下。
(2)将无标签目标域自适应深度学习用于新药筛选
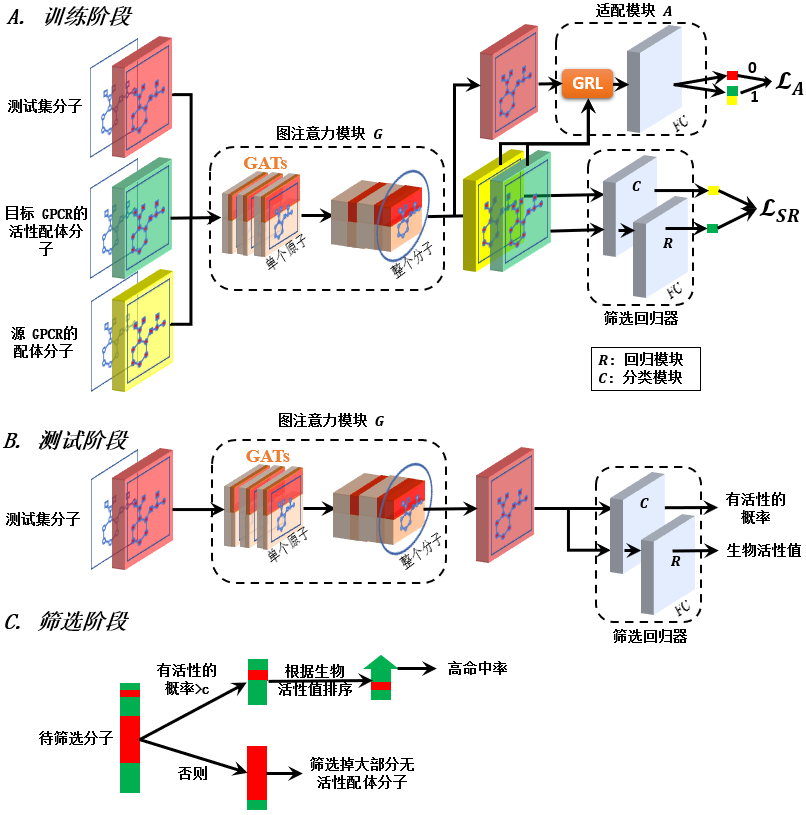
研究团队将离散的分类问题一般化为连续的回归问题,并应用于药物虚拟筛选(Virtual Screening: VS)上,进一步验证无标签目标域自适应对基于深度学习的回归模型泛化性能的提升潜力。首先,针对已测定与未测定的分子数据之间的分布差异问题,根据实际待筛选数据库的先验分布,构建新的分子虚拟筛选的标准数据集,用以综合地评价深度学习模型在实际虚拟筛选中的性能。在此基础上提出一个新的实际虚拟筛选(Real Virtual Screening: RealVS)模型。该模型从其他相关靶标的数据中迁移丰富的源域信息,利用域自适应理论适配迁移信息,以减少训练和测试数据分布不一致对模型泛化性能的影响,从而提升模型在目标靶标上的分类筛选能力。此外,采用图注意力机制研究了RealVS模型分类筛选结果的可解释性。实验结果表明,与常用的深度学习方法相比,所提出的RealVS模型明显提升了的分类筛选性能,且具有较强的可扩展性和鲁棒性。
图像分类中的小样本集问题在药物虚拟筛选中更为明显,该问题导致深度学习模型容易过拟合于训练数据,从而难以泛化到无标签的目标域上。针对此问题,本文提出一种新的基于虚拟对抗训练的特征子空间增强(Adversarial Feature Subspace Enhancement: AFSE)技术,以进一步增强深度学习模型在小样本集条件下的泛化性能。具体地,通过特征子空间中的虚拟对抗训练,使得模型在取得更高的特征平滑度的同时,保留对活性值悬崖的表征能力,从而提高深度学习模型在小样本集目标任务上的泛化性。实验结果表明,AFSE方法可运用在多种常用图神经网络上,在大量系统构建的药物虚拟筛选数据集中,取得了多项性能的提高,包括命中高活性分子的比例、预测分子活性的精度,和按活性排序分子的匹配度。
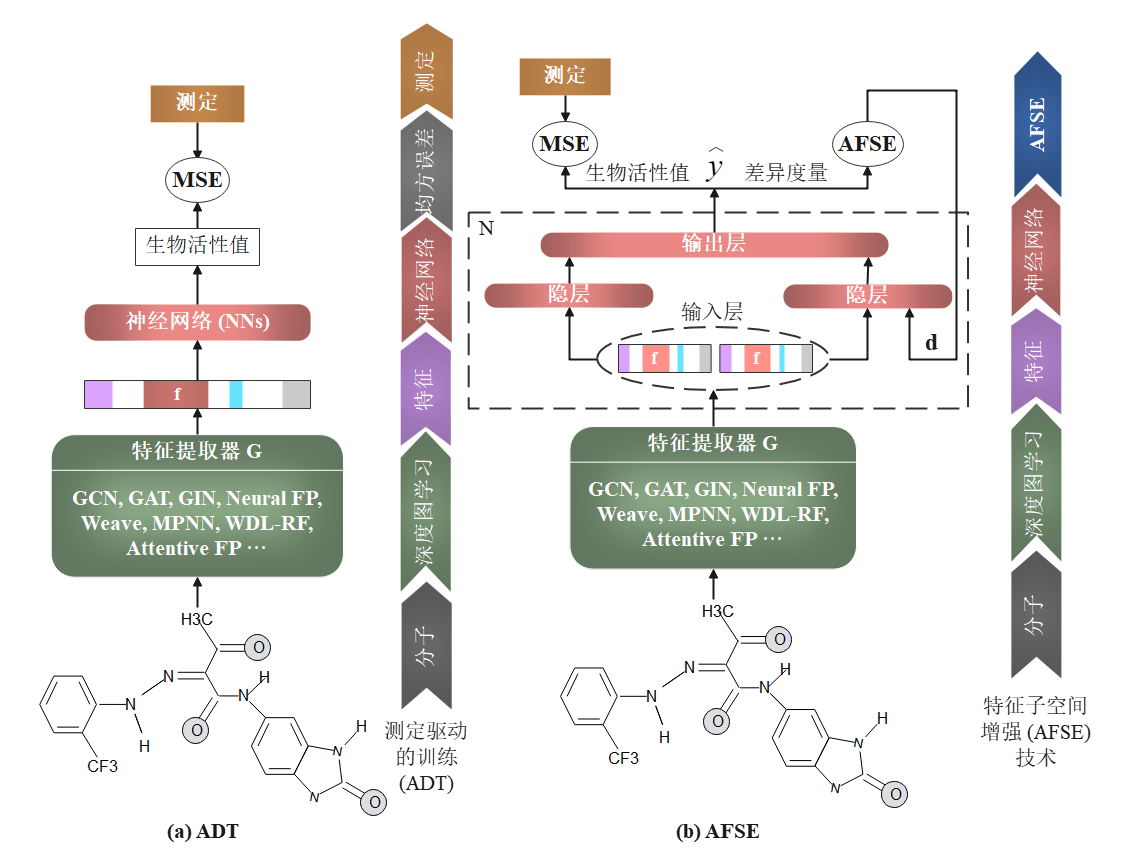
图3 基于虚拟对抗技术的对抗特征子空间增强(AFSE)小样本药物优选法
该研究方向,已完成/在研项目:
国家863重点课题“多语言语音识别关键技术研究与应用产品开发” 课题编号:2006AA010102, 1200万,杨震(副组长),完成。
国家科技支撑计划“电信运营商业务支撑软件测试与服务平台建设”项目编号:2007BAH17B04,(国拨591万),项目负责人,完成 。
国家重大基础研究计划973课题,课题名称:物联网混杂信息融合与决策研究;课题编号:2011CB302903;课题经费143万,课题负责人杨震,完成。
国家自然科学基金,基于非正交多址的认知无线网接入技术研究项目批准号:61671252,60万+,课题负责人杨震,完成。
国家自然科学基金,62071242,语音的图信号处理理论与技术研究;54万,项目负责人,在研。
该研究方向,申报发明专利20多项,授权专利8项。